To totally unlock this section you need to Log-in
Login
If you’re only indexing to make reads faster, you need to think again. Indexes can make every operation in the database faster, even deletes.
The actual deletion of a row is a similar process to inserting a new one—especially the removal of the references from the indexes and the activities to keep the index trees in balance.
In theory, we would expect the best delete performance for a table without any indexes—as it is for insert. If there is no index, however, the database must read the full table to find the rows to be deleted. That means deleting the row would be fast but finding would be very slow.
What Happens During a Delete?
When you try to delete a row, a few things happen. SQL Server says “OK, let’s make sure that we can actually delete this row, what else depends on it?” SQL Server will check for dependent rows by examining all foreign keys. It will then check any related tables for data. If there is an index, SQL Server will use that index to check for related data. If there isn’t an index, though, SQL Server will have to scan the table for data.
Deletes and Table Scans
Make a new database. Copy data in from the Sales.SalesOrderHeader and Sales.SalesOrderDetail tables in AdventureWorks (a Microsoft template database). We use the Import Data wizard to quickly copy data from one database to another.
ALTER TABLE Sales.SalesOrderHeader ADD CONSTRAINT PK_SalesOrderHeader PRIMARY KEY (SalesOrderID); ALTER TABLE Sales.SalesOrderDetail ADD CONSTRAINT PK_SalesOrderDetail PRIMARY KEY (SalesOrderDetailID); ALTER TABLE Sales.SalesOrderDetail ADD CONSTRAINT FK_SalesOrderDetail_SalesOrderHeader FOREIGN KEY (SalesOrderID) REFERENCES Sales.SalesOrderHeader(SalesOrderID) ON DELETE CASCADE;
With these three statements in place, we’re able to create a situation where SQL Server has to perform a full table scan just to delete a single row. Make sure you’ve told SQL Server to include the actual execution plan and run this:
DELETE FROM Sales.SalesOrderHeader WHERE SalesOrderID = 51721;
Once that query runs, the execution plan is going to look a bit like the execution plan below. If you add it up, 99% of the work comes from finding the rows to delete in the SalesOrderDetail table and then actually deleting them.
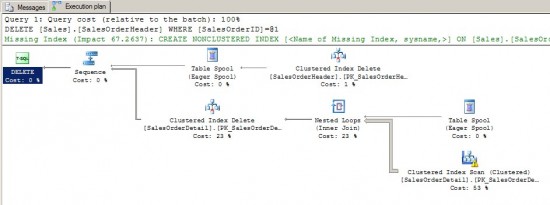
Making Deletes Faster
How would we go about making deletes like this faster? By adding an index, of course. Astute readers will have noticed the missing index information in that execution plan we took a screenshot of. In this case, the missing index looks something like this:
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_SalesOrderID ON Sales.SalesOrderDetail(SalesOrderID);
Before adding the index, the query had a cost of 2.35678. After adding the index, the delete has a cost of 0.0373635. To put it another way: adding one index made the delete operation 63 times faster. When you have a busy environment, even tiny changes like this one can make it faster to find and delete records in the database.
A delete statement without where clause is an obvious example in which the database cannot use an index, although this is a special case that has its own SQL command: truncate table. This command has the same effect as delete without where except that it deletes all rows in one shot.
 |  |